Press, PR & Media
AI LENS Workshop: AUTOPROMPT

Richard Ramchurn recently ran a workshop at the Virtual and Immersive Production (VIP) Studio, University of Nottingham, to test a new development within AI LENS called AUTOPROMPT – a system designed to generate prompts dynamically from a live scene.
As a filmmaker, artist, and researcher working with real-time generative systems, Richard is interested in how AI can be engaged through embodied interaction rather than fixed interfaces. AUTOPROMPT is a step toward that, shifting prompting into something that emerges through performance.
The system has been developed with Kieran Woodward leading on the programming of AUTOPROMPT. Together, they have been exploring how multiple AI processes can work in parallel to analyse what is happening in front of the camera and then translate that into an evolving prompt. During the workshop, that included live video analysis, speech transcription, and interpretation of vocal tone, all feeding into the generative pipeline of AI LENS.
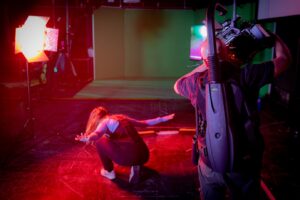
Richard explained:
“I worked with Kerryn Wise and Ben Neil alongside dancer Scarlett Perdereau, structuring the workshop as a series of short experimental vignettes, each focusing on a different modality. This allowed us to isolate how movement, speech, and vocal qualities shaped the system’s behaviour. Rather than choreographing the dancers, I invited them to improvise within each vignette, creating space for interaction with the system to develop in real time.
What emerged was a continuous feedback loop between the performers and the generated image. The dancers began to adjust their movement in response to what they saw, while the system continued to reinterpret their actions through the evolving prompt. Over time, this became less about direct control and more about developing a sensitivity to how the system responded. Small shifts in timing, intensity, or spatial relationship began to produce noticeably different results.
Working in vignette form made it possible to compare how different inputs operated. In some cases, the connection between action and image felt immediate and readable. In others, the system produced responses that were more difficult to anticipate, which pushed the dancers to explore different strategies of engagement. These variations became a key part of the process, shaping both the performance and my understanding of the system.
Alongside this, I was able to work closely with the system itself, adjusting parameters and observing how different configurations affected the interaction. This introduced another layer of responsiveness, where the behaviour of AUTOPROMPT could be tuned in parallel with the live performance.
For me, AUTOPROMPT frames prompting as something that unfolds through interaction rather than being set in advance. Within AI LENS, it extends the role of the camera into a sensing and interpretive system, drawing on multiple streams of input to shape the image as it is produced. This workshop is an early step, but it begins to show how performers and AI systems can co-adapt over time, and how meaning emerges through that exchange.”